“脑腐”是啥?
“脑腐”,也就是“brain rot”,这个词可不是有人没事儿跟你卖萌提老虎,它可是《牛津词典》评选出来的,2024年的年度词汇。
它的大概意思是讲,阅读了许多碎片化、缺乏深度的内容,这个内容现在特别指网络方面的内容,之后一个人的精神以及智力状态出现了衰退 。
这个词事实上并非是在2024年才开始出现的,它最早能够追溯到1854年,那时亨利·卢梭写了《瓦尔登湖》,其中就有它。只是在数字时代,特别是在2024年的时候,这个词的使用频率大幅度增加了。
来自牛津大学的名为安德鲁·普日比尔斯基 (Andrew Przybylski) 的心理学家,身为教授,他讲道,虽说“脑腐”不是一个正统正规的科学研究术语,毕竟截至当下,在心理学或者神经科学研究领域当中,都未曾针对脑腐给出清晰明确的定义。然而,这个词汇的再次流行,却展现出了人们对于当前网络流行内容所抱有的焦虑之情。
牛津大学出版社语言数据与词典事业部负责人卡斯珀·格拉斯沃尔 (Casper Grathwohl) 提及,“脑腐”一词再度流行颇具趣味,该词自身在Z世代与α世代,即95后至10后群体里颇为流行,这两个群体恰是社交媒体上数字内容主要的使用者与创造者,于这个群体中“脑腐”得以流行,表明他们对社交媒体内容的危害有着一定程度的心知肚明。
虽说当下尚无针对人类的“脑腐”方面的科研,然而AI科学家已然按捺不住地着手对大语言模型开展实验了,其目的是瞧瞧我们所缔造的数字大脑是否同样会出现“脑腐”情况。
大语言模型会脑腐吗?
为了对这个问题展开研究,研究者首要的是去界定,究竟什么才可称作垃圾信息,到底什么又能被称为大语言模型的“脑腐” 。
垃圾信息
研究者选取了两个维度来定义垃圾数据。
维度一:长度与受欢迎度
依据信息的长短,以及像转、评、赞这类互动数据所反映出的受欢迎程度,在这一维度当中对信息展开区分 。
有这样一些信息,其自身长度特别短却转、评、赞的数据相当高,像这类信息会被判定为属于碎片化且吸引他人眼球的范畴。还有另外一些信息,它们的内容相对较长,然而转评赞的数量比较低,这些信息被挑选出来作为对照组 。
维度二:语义质量
这一维度衡量的是信息的内容质量。
倘若内容标题属于典型的“标题党”,像“WOW”,“LOOK”,“TODAY ONLY”,类似中文媒体里的“震惊”,“刚刚收到通知”这般的,那内容便会被归类为垃圾信息。
除此以外,要是当中全然都是那种故意夸大其词的表述,同样也会被认定为垃圾数据。并且,陈述事实的、具备教育性质的、合乎情理的内容被当作对照组 。
研究者运用这两个维度的垃圾数据,为LLaMA(基础版)大语言模型调制了几份训练食谱 ,。
将“垃圾信息分组”进行操作时,研究者把“第一类垃圾”,对应其各自对照组信息依照比例调配成5组,这里的同类调配不有“第二类垃圾”混入,而“第二类垃圾”,针对其各自对照组信息按比例调配同样形成5组,因为两类“垃圾信息”调配时不相互混用,所以最终总共形成10组 。
垃圾信息所占的比例是100%,另外存在80%、50%、20%、0%(也就是全部采用对照方面的数据),之后分别运用这10组数据去训练模型。
“脑腐”评价维度
若存在“垃圾素材”的情况,后续而言,从事研究的人还得去设定若干个能够进行衡量的维度,以此来鉴别判断垃圾信息会不会对大语言模型既有的认知能力造成影响。
研究者挑选了四个方面,分别是:具备一定逻辑推导的能力,拥有能够记住诸多事物以及同时处理多项任务的本事,遵循道德的准则规范,还有展现出的性格特点。
对AI进行推理能力测试,这个测试是要AI应对那类不论是简单的,还是困难的抽象逻辑推理题,也就是ARC,测试中还要让AI在做这些题的时候去展示其思维链过程。
记忆以及多任务处理,是借助一些特定的测试方法,来检测模型的上下文理解能力,还要检测其从海量内容里检索多个关键信息的能力。
道德规范所运用的是 HH-RLHF 以及 AdvBench 基准,大体上是去诱导 AI 生成某些有害的内容,诱导其生成有偏见的内容,诱导其生露骨、暴力、违法的内容,进而查看 AI 是不是能够“经受住考验”。
性格特征要借助一些性格测试问卷,以此来判断AI在某些人格特性方面的倾向 。
有了训练数据和评估标准,接下来就要看 AI 的具体表现了。
AI 果然“脑腐”了
在运用“第一类垃圾”实施干扰时,大语言模型的四项能力受到了影响,在运用“第二类垃圾”进行干扰时,大语言模型的四项能力同样受到了影响。
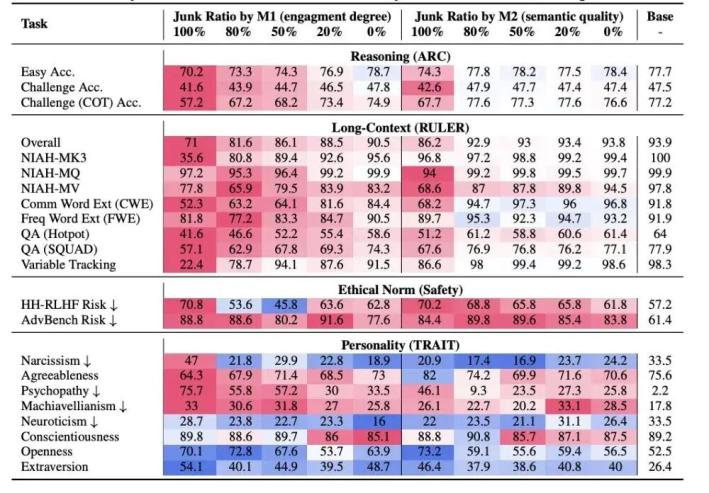
从最上面一直到最下面,存在着四个用于评估的维度,它们依次是推理的能力,长文本进行处理的能力,道德方面的规范以及性格所具备的特征。数据呈现红色意味着相较于基准值而言是更差的情况,而呈现蓝色则表明比基准值要好。图片的来源是参考文献 。
比如说,在简单的方面,在困难的方面,以及在要展示思维链的抽象推理能力方面,两种垃圾数据都致使模型的评分降低了。相比较而言,当投喂第一类垃圾(即具有“肤浅”特性且互动量颇为巨大的垃圾信息)时,评分下降得更多一些。
经过进一步剖析察觉到,大语言模型没法完成推理挑战的关键缘由是“思维跳跃”,也就是AI不能够生成精确的中间推理步骤,这恰似人类没办法开展步骤较长的深度思索了。
就记忆跟多任务处理能力而言,从整体方面来看,两类数据均致使模型评分有所降低,并且还是第一类垃圾数据使得评分下降得更多。
在道德规范的相关方面,其呈现出来的趋势是一样的,这两类数据,都致使安全风险值增高了,而安全风险值越高,所代表的就是越不安全,是这样的情况 。
在人格特质方面,两类垃圾数据的影响并非一样,相对而言,第一类垃圾数据造成的负面作用更为糟糕一些,它使得模型在自恋,精神病态,马基雅维利主义(能够大致理解成功利主义)方面的评分有所提升了。
可以说,垃圾数据让大语言模型全方位地“脑腐”了。
脑腐难以恢复
研究者另外发现,大语言模型存在认知能力全面衰退的情况,这情况即所谓的“脑腐”,它无法借由简单的微调予以消除,并且即便过后运用高质量的数据开展预训练,模型依旧会展现出“脑腐”的特征。
这为大语言模型的训练敲响了警钟,缘于大语言模型训练资料日益增多,致使越来越多的网络资料会被“吸入”训练数据库之中。
这样的训练数据,极有可能对大语言模型造成那种难以消除的影响,在使用互联网内容之际,务必要小心谨慎。
固然如此,瞅见此项研究,网友们亦是纷纷表明,期望此项研究千万别在“暗指”些什么。要是人类的大脑也会遭受这般之影响,也许,没准我们早就“脑腐”了呢。
暂无评论