我们已然习以为常于AI于屏幕之上口若悬河、生成美图,仿若其无所不晓。然而倘若将其“置于”一个真切的手术室之中,让之以主刀医生的首要视角去判定接下来该选用哪把钳子,这位“学霸”极有可能瞬间陷入茫然 。。
关乎此类问题,EgoCross项目团队着重于跨域第一人称视角视频问答评测,新工作系统展现出当下在外科、工业、极限运动以及动物视角等各种场景里现有MLLM 的全面泛化瓶颈,。
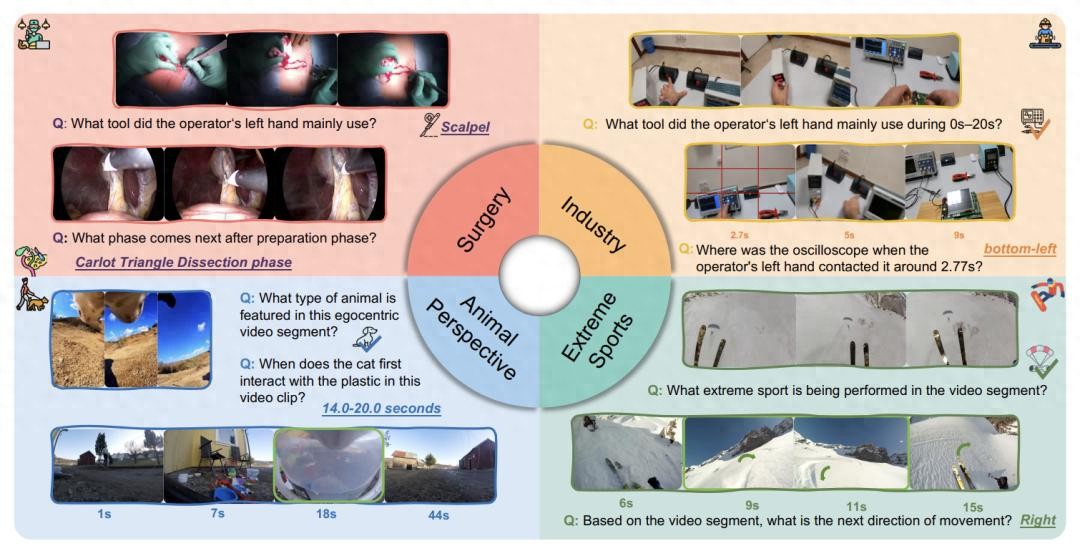
多数主要的第一人称视频基准,当下都聚焦于日常的生活活动,然而却漠视了真实世界应用里显著的领域差异。
来自华东师范大学的研究团队,和来自INSAIT的研究团队,首次提出了跨域第一视角视频问答基准EgoCross,它覆盖4个高价值专业领域,包含近千条高质量QA对,同时还提供闭卷也就是CloseQA的评测格式,以及开卷也就是OpenQA的评测格式,彻底填补了该领域的评估空白。
与此同时,团队借助8款主流MLLM展开全面测试,进而揭示出了现有模型在跨域方面存在的短板,并且验证了诸如微调(SFT)、强化学习(RL)等方法所具备的改进潜力。
此刻,该项研究已然被选入AAAI 2026,种种数据集、代码统统已完全开源。
打破日常“舒适圈”
Egocentric Video Question Answering(即 EgocentricQA)的目标,在于使得模型,在处于“第一视角视频 + 问题”这样的输入状况下,能够给出正确的、自然的语言回答。
现在,有大量工作在这一方向上取得了进展,然而,几乎所有这些工作全都仅仅是在日常生活场景当中去评测模型,这些场景包括做饭,包括切菜,还包括整理房间等等 。
现实中,更具挑战的场景往往来自:
手术领域方面,不但得识别“切割工具”,而且还得区分像“抓钳”、“手术刀”以及“双极镊”这类精细器械。与此同时,手术流程漫长,风险又高,识别以及预测错误所带来的风险极大。工业领域,涉及到复杂的电路板维修流程以及精细物体识别。极限运动,第一视角相机剧烈抖动,视角切换频繁,画面模糊严重。动物视角,相机随动物做不规则运动,视角高度和关注区域与人类完全不一样。
这些场景,在视觉风格方面,跟在语义内容那儿相比较,双双和“日常家务”存在着极大的不同,由此构成了天然存在的领域差异,也就是domain shift 。
此便诱发了本研究的关键问题,即当下于日常场景里展现出色的MLLM,其在这些陌生范畴中能否依旧值得信赖?倘若不行,症结究竟何在?又该怎样加以改良?
一个基准,三大贡献
1. 首个跨域EgocentricQA基准
用心挑选四个具备实际运用价值的专业范畴,分别为手术,还有工业,再者极限运动,以及动物视角 。
构建了包含957个问答对的数据集,覆盖15种细粒度任务类型
每一个问答对,都同时给出开放式也就是OpenQA的格式,还给出选择式也就是CloseQA的格式 。
2. 全面模型评估与分析
评判了8个处于最前沿的多模态大语言模型,其中涵盖能如GPT-4.1、Gemini 2.5 Pro这般的闭源模型,还有像Qwen2.5-VL、VideoLLaMA3等相类似的开源模型,。
经由实验所揭示的情况是,哪怕是那些在表现方面堪称最佳的模型,于跨域场景之中,其CloseQA准确率也是低于百分之五十五的,而随机猜测的准确率为百分之二十五,并且其OpenQA准确率还低于百分之三十五 。
从任务类型、领域差异、模型架构等多个维度进行了深入分析
3. 前瞻性改进研究
寻找了,提示学习也就是Prompt Learning相关技术,还探索了监督微调也就是SFT的技术,并且探究了强化学习也就是RL的技术 。
发现RL方法能带来最显著的性能提升 (平均提高22%)
为未来构建更具泛化能力的模型提供了方向
详解EgoCross:如何构建四大领域的“专业考题”?
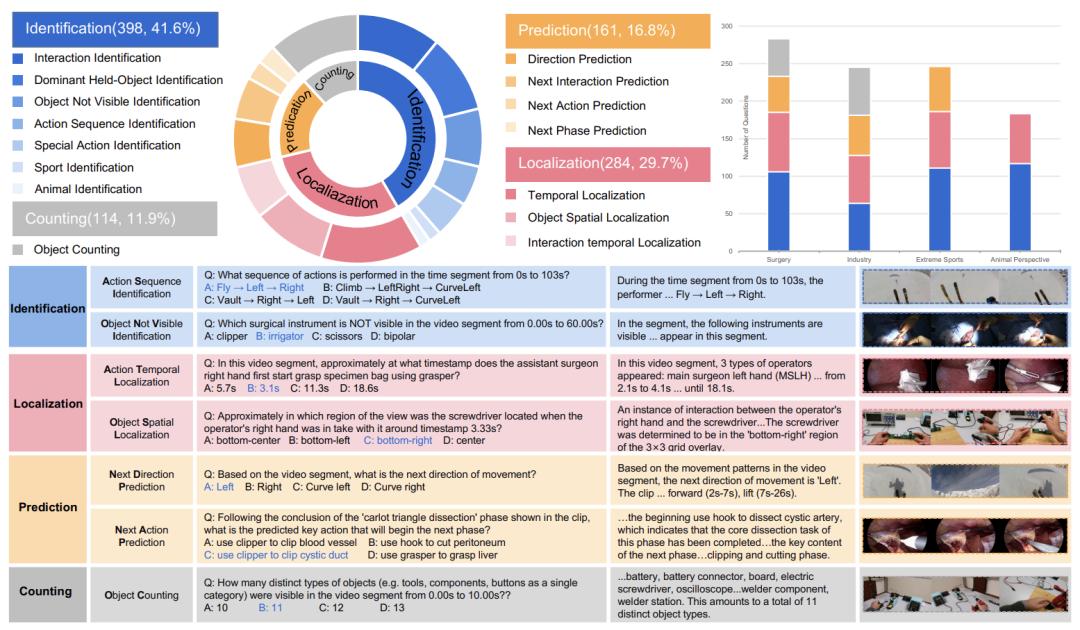
EgoCross对视频进行精选,这些视频来自五个高质量开源数据集,其涵盖四个专业领域,针对每个领域,均有四类核心任务被设计出来,分别是识别(Identification)、定位(Localization)、预测(Prediction)以及计数(Counting),这四类核心任务共有15种子任务,通过它们来全面评估模型能力。
辨认(Identification):像是动作序列辨认,还有主导手持物体辨认。像“视频里是哪一种动物呀?”“手术过程中没出现的器械是啥呢?”。
定位即叫Localization,它涵盖着时间定位以及空间定位这两方面内容,就好比“操作员于何时首次与示波器有接触呢?”,还有“螺丝刀在画面里处于哪一个区域呀?”。
预告那种行为的推测(Prediction),像是预告接下来的动作、方向或者某一阶段。就像这样的问题,“手术准备阶段完毕后紧接着的步骤是什么?”,还有“极限运动接下来的运动趋向是怎样的?” 。
计数,也就是对动态对象具备的计数能力,像“视频里能看到多少种不一样的组件?” ,这就是一种体现 。
实验揭示模型“水土不服”
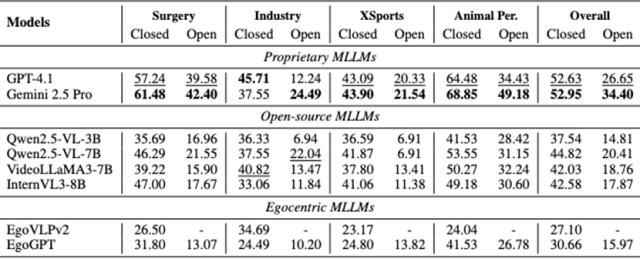
研究团队的实验揭示了几个关键发现:
领域之间存在着明显的差距了:,这样一个用来操作模仿的工具在平常的活动,也就是EgoSchema那里所获取到的准确比率是73.58%,然而呢,在EgoCross这种跨越不同领域的场景当中,这个比率一下子就降低到了43.14% 。
在专业领域之中,挑战程度更高,其中工业领域以及极限运动领域,对于模型而言,是最具备挑战性的,而动物视角方面,则相对较为容易,。
任务类型会产生这样的影响,存在预测类任务,像预测下一步操作这种,其下降程度相较于基础识别任务而言,更为严重,。
存在模型表现方面的差异,通用的大模型,也就是Gemini 2.5 Pro ,比专门针对第一人称视频有所训练的模型要好,这显示出当下领域的适应方法是有着局限的。
前瞻性改进尝试
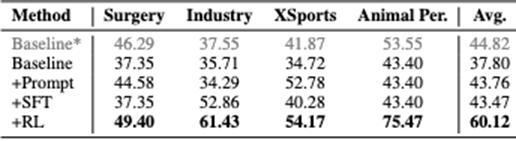
用“*”来表示基于不存在vLLM加速情况的Baseline,鉴于vLLM加速会致使出现轻微的性能向下降低的状况,所以它是以灰色进行标记的 。
研究团队探索了三种改进方法:
提示学习方面,具有这样的做法,即不改变模型参数,仅仅是在推理阶段的时候,加入领域特定的提示以及示例呢,比如说在问题之前增添“这是一个手术/工业/极限运动/动物视角的视频,请结合该领域特点回答”,通过“提词”方法去挖掘模型已有的跨域能力 。
监督微调,也就是SFT,它是以Qwen2.5 - VL - 7B作为基座,在目标领域的少量有着标注的视频问答数据之上进行全参数微调,以此让模型参数去适应新的领域分布,在工业领域方面,微调之后的性能相对基线而提升,提升幅度接近20% 。
强化学习也就是RL,基于GRPO也就是Generative Reward-based Policy Optimization搭建RL 的框架,具体的做法是这样,针对每个问题去采样多条候选回答,每条样本大概有8个,然后再使用一个奖励模型去判断答案是不是正确并且打分,把这个作为奖励信号来对Qwen2.5-VL-7B的策略进行优化。RL在四个领域上平均带来大概约22个百分点的CloseQA准确率提升,它是三种方法里效果最为明显的。
这些研究一开始就揭示出了当下大模型的能力边界,从而为往后构建更有泛化能力的多模态系统给予了宝贵的见解。
看起来,想要培育出一个不但会去做各类家务,而且还能够在专业的场景之中承担起相应事务的人工智能助手,这还得需要更多的时间去积累。毕竟,真实的世界,可不是仅仅只有厨房那般大小而已。
论文链接:
那个链接为https://arxiv.org/abs/2508.10729 ,它是一个特定的链接,指向着特定。
项目主页:
请你明确一下改写要求呀,仅给出这个链接,不太清楚具体要改写成什么样的句子呢。
挑战赛主页:
这是一个网址链接,https 开头,网址为 egocross-benchmark.github.io/ 。
暂无评论